XLA编译
-
一、简介¶
XLA的实现目录是tensorflow/compiler,目录结构如下:
| 目录名 | 功能 |
|---|---|
| aot | aot编译相关代码,前面分析的tfcompile_tool代码就在这里 |
| jit | jit编译相关代码,例如xlalaunch节点的OpKenel、XLA相关的计算图重构,都在这里 |
| plugin | 此模块看起来还没完成,暂不分析 |
| tests | 测试代码 |
| tf2xla | GraphDef转化为XLA Hlo IR代码 |
| xla | xla编译器核心代码,HLO IR转化为LLVM IR以及机器码的生成 |
XLA也是基于LLVM框架开发的,前端的输入是Graph,前端没有将Graph直接转化为LLVM IR,而是转化为了XLA的自定义的中间表示HLO IR.并且为HLO IR设计了一系列的优化器。经过优化的HLO IR接下来会被转化为LLVM IR。
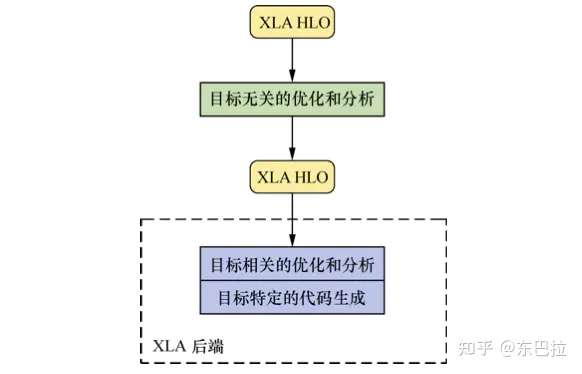
图2:XLA框架结构
具体来说包含了下列几步:
- 步骤一:由GraphDef创建Graph
- 步骤二:由tensorflow.Graph编译为HLO IR
- 步骤三:分析与优化HLO IR
- 步骤四:由HLO IR转化为llvm IR
- 步骤五:分析与优化llvm IR
- 步骤六:生成特定平台的二进制文件
xla 的使用分为 AOT和 JIT 两种模式,分别介绍如下。
## 二、AOT模式
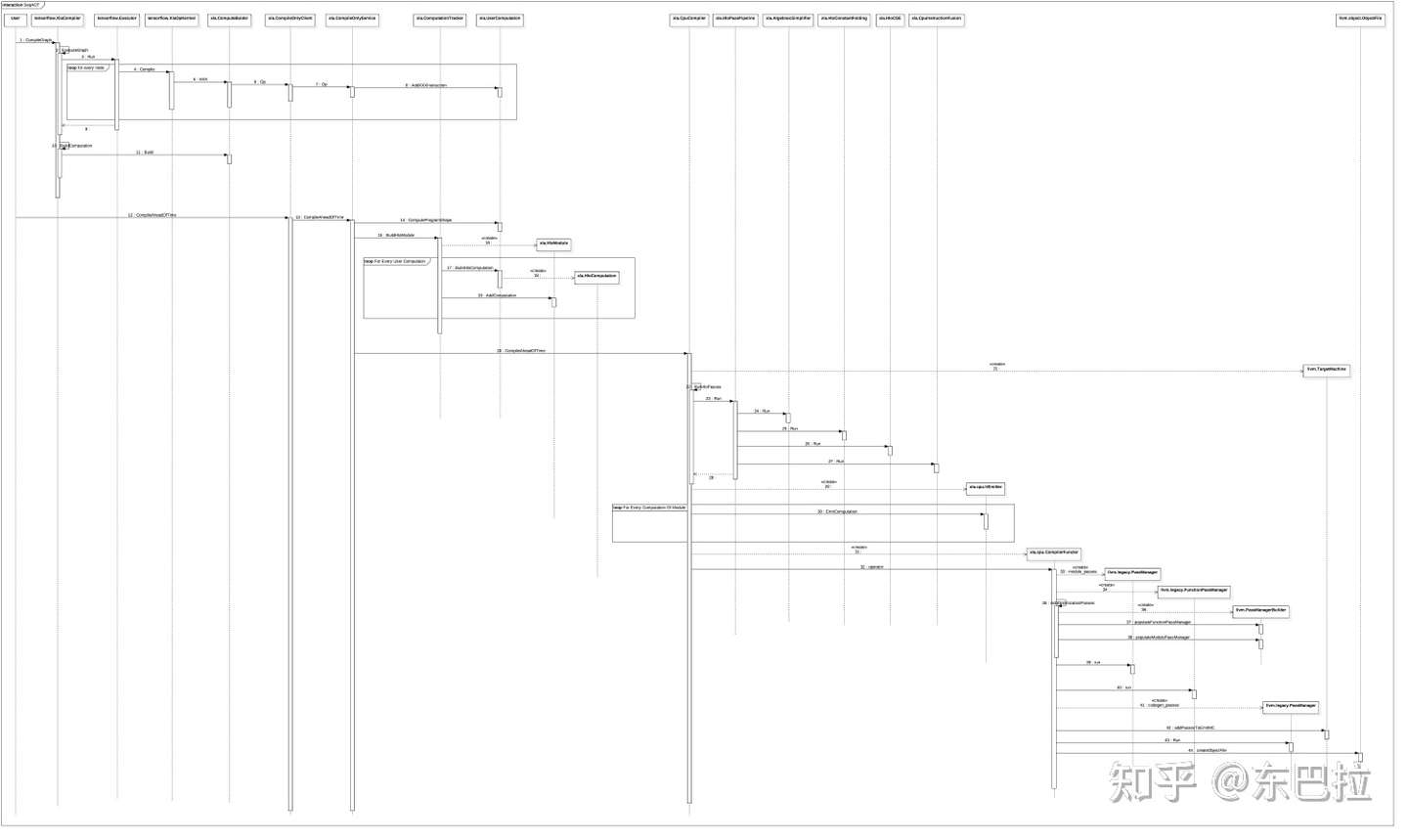
对照图2来分析一下AOT编译流程:
- tensorflow.XlaCompiler.CompilerGraph函数将Graph编译成XLA的中间表示xla.UserComputation.
- tensorflow.XlaCompiler.CompilerGraph会创建Executor来执行待编译的Graph,通过绑定设备,为所有节点的创建运算核都是专门设计用来编译的,基类是tensorflow.XlaOpKernel.
- tensorflow.XlaOpKernel的子类需要实现Compile接口,通过调用xla.ComputeBuilder接口,将本节点的运算转化为Xla指令(instruction).
- xla.ComputeBuilder是对xla.Client的调用封装,通过本接口创建的xla指令(instruction)的操作,最终都会通过xla.Client传输到xla.Service.
- xla.Client 和 xla.Service 支持单机模式和分布式模式,实际的编译过程发生在Service端.
- AOT编译中,用到的是 xla.CompileOnlyClient 和 xla.CompileOnlyService,分别是xla.Client和xla.Service的实现类.
- 可以看到,图2中的第一个循环(loop for every node)会为每个node生成一系列xla指令(instruction),这些指令最终会被加入xla.UserComputation的指令队列里。
- 接下来xla.CompileOnlyClient.CompileAheadOfTime会将xla.UserComputation编译为可执行代码.
- xla.ComputationTracker.BuildHloModule函数会将所有的xla.UserComputation转化为xla.HloComputation,并为之创建xla.HloModule.
- 至此,Graph 到 HLO IR 的转化阶段完成。
- HLO IR进入后续的编译过程,根据平台调用不同平台的具体编译器实现类,这里我们以xla.CpuComiler为例来分析.
- xla.CpuComiler的输入是xla.HloModule,首先会调用RunHloPasses创建HloPassPipeline,添加并运行一系列的HloPass.
- 每一个HloPass都实现了一类HLO指令优化逻辑。通常也是我们比较关心的逻辑所在,包含单不限于图中列举出来的 xla.AlebraicSimplifier(代数简化),xla.HloConstantFolding(常量折叠),xla.HloCSE(公共表达式消除)等。
- HloPassPipeline优化HLO IR之后,将创建xla.cpu.IrEmitter,进入图2中的第三个循环处理逻辑(loop for every computation of module):将xla.HloModule中的每个xla.HloComputation转化为llvm IR表示,并创建对应的llvm.Module.
- 至此,Hlo IR 到 llvm IR的转化阶段完成,后面进入llvm IR的处理阶段。
- 创建xla.cpu.CompilerFunctor将llvm IR转化为最终的可执行机器代码llvm.object.ObjectFile.中间会调用一系列的llvm ir pass对llvm ir进行优化处理。
- 至此,llvm ir到可执行机器码的转化阶段完成。
## 三、JIT
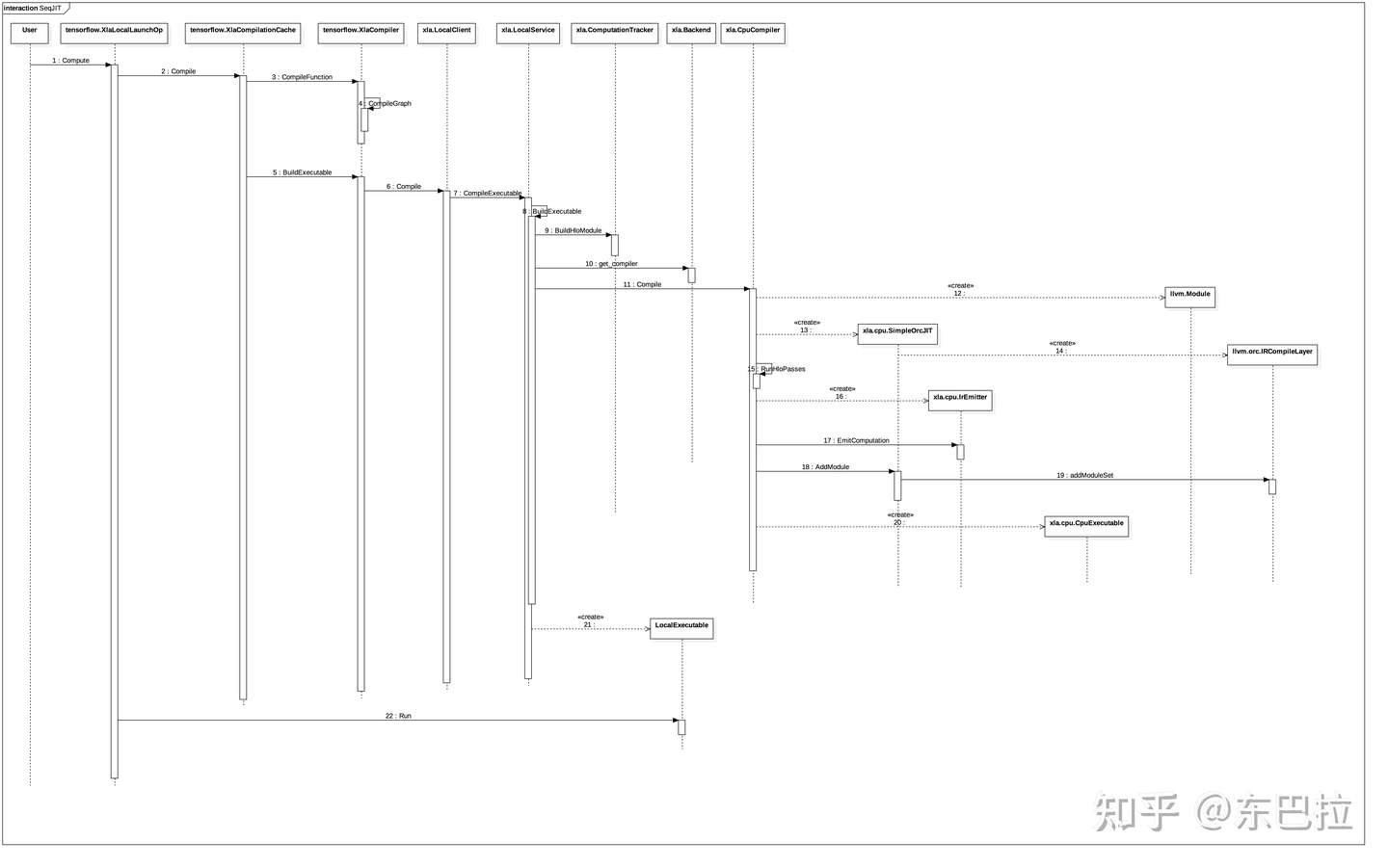
JIT对比AOT来说,过程比较类似,略过共同的部分,我们来分析一下:
- JIT调用方式的入口在运算核tensorflow.XlaLocalLaunchOp.Compute,tensorflow.XlaLocalLaunchOp是连接外部Graph的Executor和内部JIT调用的桥梁。
- 如果被调用的计算图缓存不命中,则会调用xla.XlaCompile进行实际的编译。
- 编译过程类似AOT,不同之处主要在于:首先这次调用的Client和Service的实现类是xla.LocalClient和xla.LocalService;其次,llvm ir到机器码的编译过程,这次是通过xla.cpu.SimpleOrcJIT完成的,它将llvm ir编译为可执行代码,并可被立即调用。
- 可执行机器码后续会被封装为xla.LocalExecutale
- 调用xla.LocalExecutable的如后函数Run.
## 四、通过指定环境变量编译
例子代码及运行命令(注释):
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# export TF_CPP_MIN_VLOG_LEVEL=1
# env XLA_FLAGS="--xla_dump_to=tmp/hlo --xla_dump_hlo_as_dot"
# TF_XLA_FLAGS="--tf_xla_auto_jit=2 --tf_xla_clustering_debug"
# TF_DUMP_GRAPH_PREFIX="tmp/hlo" python xla.py
import tensorflow as tf
jit_scope = tf.contrib.compiler.jit.experimental_jit_scope
x = tf.placeholder(tf.float32, name="x_hold")
y = tf.placeholder(tf.float32, name="y_hold")
z = tf.placeholder(tf.float32, name="z_hold")
with jit_scope():
x_y_sum = tf.add(x, y, name="x_y_sum")
x_y_z_sum = tf.add(x_y_sum, z, name="x_y_z_sum")
sess = tf.Session()
result = sess.run(x_y_z_sum, {x: [1.0, 2.0, 3.0, 4.0],
y: [1.0, 2.0, 3.0, 4.0],
z: [1.0, 2.0, 3.0, 4.0]})
print(result)
# 输出
# [ 3. 6. 9. 12.]
# 和大量中间文件: .pbtxt, .ll, .s
运行命令后,会生成一对.pbtxt, .ll, , .dot, .s的中间文件,包含了中间优化过程和最终的汇编文件。
## 五、使用独立工具链完成编译
### 5.1 编译llvm
$ git clone https://github.com/llvm/llvm-project.git
$ (cd llvm-project && git checkout $(cat build_tools/llvm_version.txt))
$ build_tools/build_mlir.sh ${PWD}/llvm-project/ ${PWD}/llvm-build
$ mkdir build && cd build
$ cmake .. -GNinja \
-DLLVM_ENABLE_LLD=ON \
-DCMAKE_BUILD_TYPE=Release \
-DLLVM_ENABLE_ASSERTIONS=On \
-DMLIR_DIR=${PWD}/../llvm-build/lib/cmake/mlir
$ ninja check-mlir-hlo
### 5.2 编译tfcompile
TensorFlow 计算图通常由 TensorFlow 运行时执行。在执行计算图中的每个节点时,均会产生一定的运行时开销。这也会导致二进制文件更大,因为除了计算图本身以外,还需包含 TensorFlow 运行时代码。由 tfcompile 生成的可执行代码不会使用 TensorFlow 运行时,而仅仅依赖于计算实际使用的内核。
编译器基于 XLA 框架构建。tensorflow/compiler 下提供了用于将 TensorFlow 桥接到 XLA 框架的代码。
编译:
# bazel build tensorflow/compiler/xla/tools:interactive_graphviz
bazel build tensorflow/compiler/aot:tfcompile
运行:
# bazel-bin/tensorflow/compiler/xla/tools/interactive_graphviz --hlo_text=/tmp/foo/module_0000.before_optimizations.txt --platform=cpu
tfcompile --graph=mygraph.pb --config=myfile.pbtxt --cpp_class="mynamespace::MyComputation"
### 5.3 编译tf-opt和tf-mlir-translate
(1)克隆仓库
(2)设置LLVM变量
此处注意应当把llvm-project仓库回退到相应版本,具体回退版本要参考tensorflow/third_party路径下的commit ID
$ (cd llvm-project && git checkout $(cat build_tools/llvm_version.txt))
$ LLVM_SRC=<path to llvm-project>/
(3)生成workspace文件
(4)拷贝bazel BUILD文件
cd tensorflow
cp third_party/llvm/llvm.autogenerated.BUILD LLVM_SRC/llvm/BUILD
cp third_party/mlir/BUILD LLVM_SRC/mlir
cp third_party/mlir/test.BUILD LLVM_SRC/mlir/test/BUILD
(5)构建tf-opt & tf-mlir-translate
$ bazel build --override_repository=llvm-project=$LLVM_SRC -c opt tensorflow/compiler/mlir:tf-opt
$ bazel build --override_repository=llvm-project=$LLVM_SRC -c opt tensorflow/compiler/mlir:tf-mlir-translate
构建完成后,工具链在tensorflow/bazel-bin/tensorflow/compiler/mlir路径下。
如果出现报错:
error running 'git fetch origin refs/heads/*:refs/remotes/origin/* refs/tags/*:refs/tags/*' while working with @io_bazel_rules_docker: Timed out
解决方法:在tensorflow/WORKSPACE中添加: